Home » 2017
Yearly Archives: 2017

Inventing Languages – how to teach linguistics to school students
Last week was a busy week at Queen Mary Linguistics. Coppe van Urk and I ran a week long summer school aimed at Year 10 students from schools in East and South London on Constructing a Language. We were brilliantly assisted by two student ambassadors (Dina and Sharika) who, although their degrees are in literature rather than linguistics, are clearly linguists at heart! We spent about 20 hours with the students, and Sharika and Dina gave them a break from us and took them for lunch. The idea behind the summer school, which was funded as part of Queen Mary’s Widening Participation scheme, was to introduce some linguistics into the experience of school students.
In the summer school, we talked about sounds (phonetics), syllable structures (phonology), how words change for grammatical number and tense (morphology), and word order, agreement and case (syntax). We did this mainly through showing the students examples of invented languages (Tolkien’s Sindarin, Peterson‘s Dothraki, Okrand’s Klingon, my own Warig, Nolan‘s Parseltongue, and various others). Coppe and I had to do some quick fieldwork on these languages (using the internet as our consultant!) to get examples of the kinds of sounds and structures we were after. The very first day saw the students creating a cacophony of uvular stops, gargling on velars, and hissing out pharyngeal fricatives. One spooky, and somewhat spine-chilling, moment was the entire class, in chorus, eerily whispering Harry Potter’s Parseltongue injunction to the snake attacking Seumas:
leave.2sg.erg him go.2sg.abs away
“Leave him! Go away!”
During the ensuing five days, the students invented their own sound systems and syllable structures, their own morphological and syntactic rules. As well as giving them examples from Constructed Languages, we also snuck in examples of natural languages which did weird things (paucals, remote pasts, rare word orders, highly complex (polysynthetic) word structures). Francis Nolan, Professor of Phonetics at Cambridge, and inventor of Parseltongue, gave us a special guest lecture on his experiences of creating the language for the Harry Potter films, and how he snuck a lot of interesting linguistics into it (we got to see Praat diagrams of a snake language!). In addition to all this, Daniel Harbour, another colleague at Queen Mary, did a special session on how writing systems develop, and the students came up with their own systems of writing for their languages.
The work that the students did was amazing. We had languages with only VC(C) syllable structures, including phonological rules to delete initial vowels under certain circumstances; writing systems designed to match the technology and history of the speakers (including ox-plough (boustrophedon) systems that zigzagged back and forth across the page); languages where word order varied depending on the gender of the speaker; partial infixed reduplication for paucal with full reduplication for plural; writing systems adapted to be maximally efficient in how to represent reduplication (the students loved reduplication!); circumfixal tense marking with incorporated directionals; independent tense markers appearing initially in verb-initial orders, and a whole ton of other, linguistically extremely cool, features. The most impressive aspect of this, for me at least, was just how creative and engaged the students were in taking quite abstract concepts and using them to invent their language.
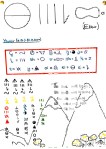
For me, and for Coppe, the week was exhausting, but hugely worthwhile. I was really inspired to see what the students could do, and it made me realise more clearly than ever, that linguistics, often thought of as remote, abstract, and forbidding, can be a subject that school students can engage with. For your delectation, here are the posters that the students made for their languages.








Syntax: still autonomous after all these years!
Another day, another paper. This time a rumination on Chomsky’s Syntactic Structures arguments about the autonomy of syntax. I think, despite Fritz Newmeyer’s excellent attempts to clear this issue up over many years, it’s still reflexively misunderstood by many people outside of generative grammar. Chomsky’s claim that syntax is autonomous is really just a claim that there is syntax. Not that there’s not semantics intimately connected to that syntax. Not that syntactic structures aren’t susceptible to frequency or processing effects in use. Just that syntax exists.
Current alternatives to the generative approach to dealing with language still, as far as I can tell, attempt to argue that syntactic phenomena can be reduced to some kind of stochastic effect, or to some kind of extra-linguistic cognitive semantic structures, or to both. This paper attempts to look at the kinds of arguments that Chomsky gave back in the 1950s and to examine whether the last 60 years have given us any evidence that the far more powerful stochastic and/or cognitive semantic systems now available can do the job, and eliminate syntax. I guess most people that know me will be unsurprised by my conclusion: even the jazziest up-to-the-minute neural net processors that Google uses still don’t come close to doing what a 3 year old child does, and even appealing to rich cognitive structures of the sort that there is good evidence for from cognitive psychology misses a trick when trying to explain even the simplest syntactic facts. I look at recent work by Tal Linzen and colleagues that shows that neural net learners may mimic some aspects of syntactic hierarchy, but fail to capture the syntactic dependencies that are sensitive to such structure. I then reprise and extend an argument that Peter Svenonius and I gave a few years back about bound variable pronouns.
One area where I do signal a disagreement with the Chomsky of 60 years ago is in the semantics of grammatical categories. Chomsky argued that these lack semantics, but, since my PhD thesis back in the early 1990s, I’ve been arguing that grammatical categories have interpretations. Here I try to show that the order of Merge of these categories is a side effect not of their interpretations, but of whether the kind of computational task they are put to is more easily handled with one order or the other.
The idea goes like this (excerpted from section 4 of the paper).
“Take an example like the following:
(20) a. Those three green balls
b. *Those green three balls
As is well known, the order of the demonstrative, numeral and descriptive adjective in a noun phrase follow quite specific typological patterns arguing for a hierarchy where the adjective occurs closest to the noun, the numeral occurs further away and the demonstrative is most distant (Greenberg 1963, Cinque 2005). Why should this be? It seems implausible for this phenomenon to appeal to a mereological semantic structure. I’d like to propose a different way of thinking about this that relies on the way that a purely autonomous syntax interfaces with the systems of thought. Imagine we have a bowl which has red and green ping pong balls in it. Assume a task (a non-linguistic task) which is to identify a particular group of three green balls. Two computations will allow success in this task:
(21) a. select all the green balls
b. take all subsets of three of the output of (a)
c. identify one such subset.
(22) a. take all subsets of three balls
b. for each subset, select only those that have green balls in them
c. identify one such subset
Both of these computations achieve the desired result. However, there is clearly a difference in the complexity of each. The second computation requires holding in memory a multidimensional array of all the subsets of three balls, and then computing which of these subsets involve only green balls.
The first simply separates out all the green balls, and then takes a much smaller partitioning of these into subsets involving three. So applying the semantic function of colour before that of counting is a less resource intensive computation. Of course, this kind of computation is not specific to colour—the same argument can be made for many of the kinds of properties of items that are encoded by intersective and subsective adjectives.
If such an approach can be generalized, then there is no need to fix the order of adjectival vs. numeral modifiers in the noun phrase as part of an autonomous system. It is the interface between a computational system that delivers a hierarchy, and the use to which that system is put in an independent computational task of identifying referents, plus a principle that favours systems that minimize computation, that leads to the final organization. The syntax reifies the simpler computation via a hierarchy of categories.
This means that one need not stipulate the order in UG, nor, in fact, derive the order from the input. The content and hierarchical sequence of the elements in the syntax is delivered by the interface between two distinct systems. This can take place over developmental timescales, and is, of course, likely to be reinforced by the linguistic input, though not determined by it.
Orders that are not isomorphic to the easiest computations are allowed by UG, but are pruned away during development because the system ossifies the simpler computation. Such an explanation relies on a generative system that provides the structure which the semantic systems fill with content.
The full ordering of the content of elements in a syntactic hierarchy presumably involves a multiplicity of sub ordering effects, some due to differences in what variable is being elaborated as in Ramchand and Svenonius’s proposal, others, if my sketch of an approach to the noun phrase is correct, due to an overall minimizing of the computation of the use of the structure in referring, describing, presenting etc. In this approach, the job of the core syntactic principles is to create structures which have an unbounded hierarchical depth and which are composed of discrete elements combined in particular ways. But the job of populating these structures with content is delegated to how they interface with other systems.”
The rest of the paper goes on to argue that even though the content of the categories that syntax works with may very well come from language external systems, how they are coopted by the linguistics system, and which content is so coopted, still means that there is strong autonomy of syntax.
The paper, which is to appear in a volume marking the 60th anniversary of the publication of syntactic structures is on Lingbuzz here.
A Menagerie of Merges
I’ve been railing on for a while about this issue, but have just finished a brief paper which I’ve Lingbuzzed, so thought it deserved a blogette. My fundamental concern is about the relationship between restrictiveness and simplicity in syntactic theory. An easy means of restricting the yield of a generative system is to place extra conditions on its operation with the result that the system as a whole becomes more complex. Simplifying a system typically involves reducing or removing these extra conditions, potentially leading to a loss of restrictiveness.
Chomsky’s introduction of the operation Merge, and the unification of displacement and structure building operations that it accomplishes, was a marked step forward in terms of simplifying the structure building component of generative grammar. But the simplicity of the standard inductive definition of syntactic objects that incorporates Merge has opened up a vast range of novel derivational types. Recent years have seen for example, derivations that involve rollup head movement, head-movement to specifier followed by morphological merger (Matushansky), rollup phrasal movement (Koopman, Sportiche, Cinque, Svenonius and many others), undermerge (Pesetsky. Yuan), countercyclic tucking-in movements (Richards), countercyclic late Merge (Takahashi, Hulsey, and the MIT crowd in general), and, the topic of this brief paper, sidewards movement, or, equivalently, Parallel Merge (Nunes, Hornstein, Citko, Johnson).
An alternative to adding conditions to a generative system as a means of restricting its outputs is to build the architecture of the system in such a way that it allows only a restricted range of derivational types, that is, to aim for an architecture that embodies the constraints rather than representing them explicitly (cf. Pylyshyn’s Razor). This opens up the possibility of both restricting a system and simplifying it. In my Syntax of Substance book for example, I argued for a system that does not project functional categories as heads, following Brody’s Telescoped Trees idea. This immediately removes derivational types involving certain kinds of head movement from the computational system. Apparent head movement effects have to be, rather, a kind of direct morphologization of syntactic units in certain configurations. No heads means no rollup head movement, no head to specifier movement followed by morphological merger, no `undermerge’ and no parallel merge derivations for head movement (a la Bobaljik and Brown). That same system (Adger 2013) also rules out roll-up phrasal movements via an interaction between the structure building and labelling components of the grammar (essentially, roll-up configurations lead to structures with two complements). It follows that the kinds of roll-up remnant derivations argued for by Kayne and Cinque are ungenerable and the empirical effects they handle must be dealt with otherwise. In all of these cases the concern was to reduce the range of derivational types by constructing a system whose architecture simply does not allow them. Adger 2013 makes the argument that the system presented there is at least no more complex than standard Bare Phrase Structure architectures.
In the draft paper I just posted, I’ve tried to tackle the issue of Sidewards Movement/Parallel Merge derivations, by attributing a memory architecture to Merge. The basic idea, which I presented in my Baggett lectures last year, is to split the workspace into two, mimicking a kind of cache/register structure that we see in the architecture of many computers. One workspace contains the resources for the derivation (I call it the Resource Space) and the other is a smaller (indeed binary) space that is where Merge applies, which I call the Operating Space. So a syntactic derivation essentially involves reading and writing things to and from the Operating Space, where the actual combination takes place.
This architecture makes Parallel Merge derivations impossible, as there is just not enough space/memory in the Operating Space to have the three elements that are needed for such a derivation. This is really just a way of formally making good on Chomsky’s observation that Parallel Merge/Sideways Movement derivations are in some sense ternary.
In the paper I define the formal system that has this result, and argue that it makes sense of the fact that the two gaps in a parasitic gap construction do not behave interpretively identical, extending some old observations of Alan Munn’s. But the main point is really to try to reduce the range of derivational types, and hence the restrictiveness of the system, without explicitly constraining the computational operations themselves. The extra complexity, such as it is, is actually a means of simplifying or economising memory in the computational system.
The paper is here.
