Blog
Mereological Syntax
So I finished a new book a week or so back, and since I’m not really using the hideous mess that twitter has become, I thought people might be interested in the overall argument. The book is off under review just now, but I gave a talk about some of the ideas both at GLOW and more recently at QMUL. The QMUL slides are here.

The argument of the book starts from some history. Chomsky’s 1955 magnum opus, The Logical Structure of Linguistic Theory, delineated a view of syntactic objects as sets of strings. I trace the arguments about the nature of syntactic objects through the 1970s and 1980s, focussing on Stowell’s development of the X-bar theoretic view, the reasons why order was removed from the theory, and then the minimalist critique that Chomsky developed of the X-bar theoretic perspective in the early 1990s, his introduction of the operation Merge, and various changes of perspective about what Merge does, and why it does it since. I then focus on two shortcomings of that model. The first is that when Merge builds a set-theoretic object, that new object needs to be categorized (have a label) and that requires a new sub-theory to do the labelling. The second is that the way that Merge models long distance dependencies is via the construction of `copies’ of syntactic objects. But these copies also require a special sub-theory to distinguish them from items that are formally identical, but not constructed via Merge operating long distance. I argue it would be better to have a system that didn’t require these extra sub-theories.
I then develop a new system based on the fundamental idea that syntactic objects are not set-theoretic but rather they are mereological. Usually, in linguistics, classical extensional mereology is appealed to in the analysis of mass terms, plurals, imperfective aspect etc., and its attractiveness in these domains is because it provides a way of modelling undifferentiated parthood. However, syntactic objects are clearly highly differentiated, so classical mereology is insufficient. Instead I introduce the notion of a hylomorphic pluralistic mereological system from the work of philosophers like Fine and Koslicki, and argue that this is a better model for phrase structure than sets. Hylomorphic mereologies take objects to consist not just of their parts, but also of the way that their parts are composed, and pluralistic mereologies allow parts to be part of objects in different ways (what I call dimensions of parthood). This provides the required differentiation. The core notion of mereology is the notion (proper) part, which is an Irreflexive Transitive relation (compared to set-membership, which is an Irreflexive Intransitive relation). I therefore define an alternative to Merge, which I call Subjoin, which takes two objects and makes one of them part of the other. I also show how the point in a derivation can be used to differentiate different `dimensions’ of parthood. Subjoin provides the way that parts are parts of their whole, and dimensions provide the different `flavours’ of that combinatory mechanism. I suggest that the dimensions distinguish extended projection complement relations from specifier relations. This new system, it turns out, is no more complex than the set theoretic system, but it needs no special subtheory for labels (since, when you make an object part of another object, nothing changes in terms of the labels). It also derives syntactic objects where a single object can be part of multiple other objects, rather than requiring copies, so the system is a multidominance (or rather multiparthood) system, meaning that it is straightforward to distinguish `copies’ from non-copies. The chapter concludes that the new system is at least as simple as the standard set theoretic system, but an improvement in that it suffers neither from the labelling nor from the copy problems.
I then turn to the implications of the mereological approach for theories of locality. I show how a simple extension of the most local relations between objects in the system provides a theory of locality that answers four questions which are not properly answered by the standard system: why are there locality domains? Why are they what they are? Why are there exceptions to locality domains? Why are these what they are? In the mereological theory of syntactic objects, there are locality domains because the part relation is Transitive, but Dimensionality blocks that relation. This means that some syntactic objects are parts of another object, but they are not part of that object in a consistent dimension. If syntax `sees’ parts only via dimensions, then those ‘disconnected’ parts are invisible to it. The domains are what they are because of the two dimensions of syntax: essentially the innards of specifiers are `invisible’ from outside the specifier, so specifiers are locality domains. There are exceptions to those domains because of Transitivity. If something is a specifier of a specifier of an object, then Transitivity implies it is a specifier of that object. But then it is local to that object, which makes the `edges’ of specifiers transparent, while the insides of specifiers are opaque. This also answers the final question as to why the exceptions are what they are. With this theory in place, I define a locality principle (Angular Locality) which ensures the results just discussed, and show how, as a side effect, it also rules out super-local dependencies (such as one between a complement and a specifier of a category), and super-non-local dependencies (the equivalent in this system of parallel Merge and Sidewards Movement). I illustrate how the system works through an analysis of Gaelic wh-extraction, including new data about the interaction of the spellout of an object in a position to which it has subjoined, vs spellout of the object to which it has subjoined. The system also extends elegantly to partial-wh-movement constructions and clausal pied-piping as a means of expressing long-distance phrase-structural dependency. I also examine how the system maps from mereological structures, which have only hierarchical dimensionality, to linear structures which are required for most kinds of externalization of syntax (pronunciation or signing), adopting a Svenonius/Ramchand style approach to lexicaliztation of extended projections, and propose a way of essentially extending that to internally subjoined objects (moved constituents).
The bulk of the rest of the argument focusses on how the system plays out in the domain of islands, one of the most central topics in syntax since the 1960s. I first show how the system predicts wh-islands: because of the interaction between Transitivity and Dimensionality, if a syntactic object has something subjoined to it, it is impossible to subjoin something else to it. But the result that emerged from the previous chapter showed that the only possible means that an object can subjoin from inside a specifier is through that specifiers own specifier (because of the way that Transitivity works). This means that wh-islands (almost) follow from the system. The standard Bare Phrase Structure system does not have this consequence, since it allows multiple specifiers, and so has multiple positions at phase edges. This is why in the standard system, wh-islands are usually explained via minimality effects rather than phase theory. In the mereological system, they emerge through the theory of phrase structure itself. Over the past few decades, a number of exceptions have been discovered to the wh-Island effect (especially Scandinavian languages, but also Hebrew, Slovenian, some varieties of English, etc.). I adopt a perspective here based on the idea that the wh-expression is not actually at the edge, and that these languages allow a further category, which provides an extra specifier. One might think that this robs the theory of empirical bite; however, I show that it predicts a new effect, which I call the Wh-Island Re-Emergence (WIRE) effect, which is unexpected in the standard system. This effect arises because, although it is possible to subjoin an element outside of a specifier, it is not possible to extract two elements from the same specifier, because of the way that Transitivity and Dimensionality interact. I show how the WIRE effect can be detected in Norwegian, Danish, Hebrew and English. This consequence of the theory (that it is not possible to extract two elements from a single constituent) would seem to be falsified by languages, like Bulgarian, which allow multiple wh-movement, but I proffer a new analysis of this phenomenon, what I call a declustering approach, which explains not only why it is possible, but also why in such constructions only absorbed readings of the wh-quantifier are possible. I also show how the prediction, that in these languages the WIRE effect should not appear, is correct.
One of the consequences of the system is that there’s no real geometrical difference between subjects and objects, but there is a tradition in generative syntax that says that objects are more easy to extract from than subjects. I try to argue that this is wrong.
I do this by first examining nominal island effects where the nominal is in object position, both those involving extraction from prepositional complements to nouns, and clausal complements to nouns, and I argue that these all boil down to specificity effects, which, in the mereological system, emerge in the same way as wh-island effects do: an internal part of the nominal subjoins to the object which constitutes the nominal as a whole, and, by Dimensionality, blocks any further subjunction from below it. I argue that the proposal I made in my 2013 book for nominal structure should be adopted. This is the idea that apparent complements to nouns are actually introduced by functional structure which is relatively high in the noun phrase. I extend to clausal complements my previous work on adpositional phrases and show that, once this perspective is adopted, definiteness can be understood as involving subjunction to the category D. Indefinites do not involve this subjunction, and so it is predicted by the system that extraction (subjunction) is possible from indefinites; definites and specifics, in contrast, have something subjoined to D, blocking extraction and deriving Fiengo and Higginbotham’s 1981 Specificity Condition. I then extend the analysis to wh-in-situ cases like Persian and Mandarin, and how how the same effect emerges. I adduce further evidence from Mandarin that subjunction of any constituent to D gives rise to specificity effects and concomitant blocking of extraction. With this in hand, I then show how the proposals extend to Slavic languages, and provide an alternative to the widespread NP analysis of these languages. I argue that the mereological approach is an improvement over the NP analysis of these languages, as it makes a more precise prediction about the collocation of overt articles and extraction, and I appeal to data from Mayan, Bulgarian, and Austronesian languages that backs up this direction of analysis. The system also extends to some long-standing problems from the Specificity Condition, such as the Clitic Gate phenomenon in Galician and the Ezafe construction in Persian. The core difference between the systems is that in the mereological approach definiteness is syntactic, while in the Specificity Condition approaches it is semantic. This chapter also extends the theory to the extraction effects found in Scrambling constructions in Germanic, showing that classical analyses based on Huang’s Condition on Extraction Domains constraint or using the Freezing Condition, cannot be correct, and syntactic definiteness captures the empirical patterns more effectively.
I argue that the differences between weak and strong definite articles in Germanic can be understood as whether a Det category subjoins to D or not. I show how this correlates with extraction and then extend the idea to a new approach to the classical paradigm in English, where the definite article shows a weaker effect than Possessors or Demonstratives. I argue that one way of thinking about this is in terms of markedness (where by markedness I mean accessibility a particular category by the parser in the moment/context). In English, the definite determiner the is actually ambiguous, one instance being equivalent to strong articles in German, and the other equivalent to weak articles. The former obligatorily subjoins to D, the latter does not, so only the latter is compatible with extraction. The idea then is that the weak version is marked in English, so the judgement of acceptability is essentially a judgment of markedness (which I conceptualize as ease of accessibility to the parser): extraction is grammatical, but requires a weak definite parse of the definite article, and that is marked in English. I also show how this idea of weak and strong definiteness can explain a number of apparent exceptions to the Specificity Condition, such as with process nouns and superlatives, and how it can handle long-standing problems such as extraction from definite nouns that are complements of verbs of creation. Finally I show how this system extends to the classical Complex Noun Phrase Constraint (CNPC) phenomena and the exceptions to the CNPC noted by Ross in 1967, drawing into the analysis recent work on Danish which makes morphological and semantic distinctions that follow from the overall analysis. Overall the core point of the chapter is that extraction from noun phrases is fundamentally regulated by whether the noun phrase has part of it subjoined to itself, a configuration which can be detected by how it is both pronounced and interpreted.
Finally I turn to subjects. Since subjects and objects are not geometrically distinct in mereological syntax (both are specifiers, or, more technically in the system, they are 2-parts, which is a kind of transitive notion of specifierhood), the system cannot appeal to CED type factors to explain why subjects are more difficult to extract from than objects. Given that it is effectively multidominant, the system also cannot appeal to Freezing type explanations, since these rely on chain links with distinct properties. This means that subject islands also must, essentially, be specificity islands, and I show how, with a careful evaluation of the data, this turns out to be correct. In the chapter I draw on a great deal of experimental work on Subject Islands much of which emerged in an attempt to test the kinds of predictions that CED and Freezing accounts predicts, but also the predictions of Chomsky’s On Phases system, which blocks extraction from a phasal edge, but allows it to take place in parallel to both subject position and wh-scope position. I review experimental work on German, English, Russian and Hungarian, languages which have been argued to have aspects of their syntax which allow the predictions of these different accounts to be tested. I also consider the difference between pied-piped and stranded cases. In addition to the experimental work, I gather evidence from English, French, Spanish, and Greek showing that none of these accounts capture the right generalizations. I also look at more recent approaches, including those that appeal to the information-structure syntax interface, and extend some ideas that were first proposed by Bianchi and Chesi, who argue that the traditional distinctions of the On Phases theory (basically the differences between transitive, unergative and unaccusative predicates) are insufficient. I argue that this approach is on the right lines but that a mereological interpretation of it has a number of advantages, and, of course, since that system cannot appeal to CED or Freezing type accounts, it has the advantage of ruling these out as possible analyses available to the language acquirer. To capture the empirical effects, I propose that English (for example) has two categories which host surface subjects (two T categories): one of these is similar to the scrambling clausal category I proposed for German, and the other is similar to the classical analysis of English T (that it bears an EPP feature). I suggest that the former is correlated with a individual topic interpretation (a categorical construal), while the latter is interpreted as an event/stage topic interpretation (a thetic construal), providing a different implementation of Bianchi and Chesi’s ideas within the mereological system. The theory correctly predicts that it is impossible to extract from subjects that are construed as topics, but possible to extract from subjects that are not. Just like I argued for definites in English, I take there to be a markedness effect with these two T categories: it is less marked to construe the subject as a topic (i.e. to use the T associated with this interpretation) so parses of extractions from subjects must involve the more marked T, and that is why the experimental data tends to show there is an effect. I show how this accounts for the experimental data discussed earlier in the chapter, and extend it to the case of Hungarian, where I argue that Hungarian topics, which seem to be transparent to extraction just in certain cases, are actually always transparent to extraction because they bear the feature that checks topicality on D rather than on a lower category that subjoins to D (making Hungarian parallel to Persian in some respects). I briefly conclude the chapter with a discussion of relative clauses, another island effect that has been tied down to CED effects, and, appealing to recent work by Sichel on Hebrew, I show how they too involve structures which have a `free’ edge to the D category that ends up being filled in situations where they are specific or topical.
Further Consequences and Extensions
The system I develop has a number of advantages over the currently available system of phrase structure in minimalist generative linguistics. It is theoretically an improvement, as it doesn’t require extra sub-theories to deal with labelling or the copy/repetition problem; further, it leads to a theory of locality that, I think, explains why syntactic domains are local, and why the locality domains are what they are. It also has some empirical advantages, in that it predicts the WIRE effect, and its interaction with multiple wh-movement, and it captures the right lay of the empirical land in terms of extraction from nominal phrases in both subject and object positions. However, the book leaves a great deal still to do: there are two other areas of `locality’ in syntax that it doesn’t touch on. One is Williams Cycle (or Generalised Improper Movement) effects, where cross clausal dependencies seem never to target a position in the embedding clause that is lower than the position where the dependency is rooted in the embedded clause. The Williams Cycle issue is connected with the question of clause size in general, and how the system is to deal with embedded clauses that are not full CPs. The classical analysis of, for example, raising or ECM clauses is that they must be complements of the selecting verb, and they certainly seem to allow multiple extractions to take place from them, which would be ruled out in the mereological theory if they are specifiers. This means they must be complements, and then the issue becomes exactly what this implies for the interpretation of the two different types of part relation that Dimensionality derives. It also raises questions about how to deal with hyper-raising of the Zulu type (as opposed to the P’urhépecha type). The question of improper movement may, as argued in recent work by Keine and, in computational terms, by Graf, be a side effect of the kinds of head/features that are involved, and the feature theory assumed in the book is very simple, amounting to more or less the Minimalist Grammar feature theory of Stabler and others. This is an area for further development.
The second locality area is Minimality Effects of the type that Rizzi pointed out in his 1990 book. So far the system I’ve developed does not need to appeal to these. Wh-Islands are tackled via phrase structure, there is no head movement in the system because the kinds of syntactic objects it generates are headless (what Brody 2000 called `telescoped’), and, as mentioned above, A-movement Relativize Minimality effects may well depend on what the phrase structure of raising and ECM verbs is. However, there are many other cases where Relativized Minimality, or similar constaints, appear to hold (for example Beck Effects), and these currently fall outside the system.
Getting creative: the benefits of a backstory
By Maya Kigariff
Based on a project for the QMUL Linguistics Constructing a Language course

When creating a constructed language, it can be quite tempting to make it as original as possible, making choices that would be odd, or even unheard of, in natural languages in order to create a language that feels new and exciting. This isn’t a bad thing, it’s a good way to make sure that your language is different, and that it isn’t just a reconstruction of the language/s you already speak.[i]
However, the choices you make, to some extent, should have some sort of justification.Some linguists have argued that language universals exist for functional reasons, so it is important to think about why the presence or absence of these universals makes sense for your speakers.
A helpful way to do this is to create a detailed backstory for the speakers of your…
View original post 1,694 more words
Are generative grammarians abandoning innateness?
A recent blog post by Martin Haspelmath has the very Buzzfeed title: “Some (ex-)generative grammarians who are abandoning innateness”. The actual post then goes on to nuance this somewhat but Haspelmath still takes these individuals to be abandoning core tenets of generative grammar and asks:
“Are these linguists who are abandoning most of Chomsky’s programme from the 1960s through 1990s still “generative grammarians”, or are they ex-generative grammarians? How can they continue to work with the assumption of uniform building blocks, if these are not innate? I am as puzzled as was back in 2018.”
I’ll try here to clear up some of this puzzlement. It’s a long post so …
tl;dr: yes, they are still generative grammarians; the reason they work with current theories is that they recognize that theoretical posits are placeholders for future understanding. Whether a particular phenomenon is explained by a language specific innate property of the mind, or by a general cognitive capacity, or by a law of nature is something to find out, and working with current generative theories is a good way to do that.
First a few remarks about Innateness. There’s no argument that we bring innate capacities to bear when we learn languages. There is, however, a question about what these capacities are and whether they are specific to language. In a paper I wrote in response to Adele Goldberg many years ago, I distinguished three possibilities when thinking about syntax and innateness; (i) When a child is learning a language, every aspect of their innate cognitive capacities can be brought to bear in learning the syntax of their language. Learning the syntax of a language is like learning other complex skills; (ii) Cognition is innately structured so that only some aspects of the child’s innate cognitive capacities can be used for learning syntax, but these are all capacities that are used outside of language learning too; (iii) as well as the capacities used in (ii), there are some capacities that are not used elsewhere in cognition, or at least, if they are, their use there is derivative of language (counting comes to mind as a possibility). These are innate and unique to language.
Option (i) is, I think, a non-starter, for the reasons I discussed in my 2019 book, Language Unlimited (soon to be out in paperback I hear!).
The distinction between options (ii) and (iii) is, of course, Hauser, Chomsky and Fitch’s (2001) distinction between the Broad and Narrow Faculties of Language.
1980s style generative grammar (say, Government and Binding Theory) developed theories that attributed quite a lot of content and structure to the Narrow Faculty of Language: D-structure, S-structure, C-command, government, X-bar Theory, Binding Theory, particular categories and features, and all the rest of what fascinated me as an undergraduate in the 1980s. I still fondly remember reading, in the staff-room of the Edinburgh Wimpy fast food restaurant, clad in my stripy red and white dungarees and cap, van Riemsdijk and Williams’ fascinating 1987 textbook, much to the perplexity of my co-workers!
Government and Binding Theory was, I think, empirically successful, at least in terms of enriching our understanding of the syntax of lots of different languages and, though I guess Haspelmath and I differ here (see our debate in Haspelmath 2021 and Adger 2021), in uncovering some deep theoretical generalizations about human language in general. The concepts the theory made available, and the questions it raised, led to both a broader and a deeper type of syntactic investigation. It wasn’t to everyone’s taste, and many people developed alternatives, which, as anyone who’s read my views on this knows, I consider to be all to the good. I was myself, while working in that Wimpy, a budding unification categorial grammarian, sceptical of GB, though intrigued by it.
Keeping to generative grammar internal criticisms and putting aside for the moment challenges from outside that field, two things militate against simply stopping with the successes of Government and Binding as a theory of syntax. One is methodological: we should assume that the organization of things in the world is simpler than it looks because that’s been a successful strategy for deepening understanding in the past; the other is more phenotypical: how did the Narrow Faculty of Language get so complex, given the apparently brief evolutionary time over which it appeared?
Minimalism: Hence the appearance, almost three decades ago, of Minimalism. I first encountered it through the 1992 MIT Occasional Papers version of Chomsky’s paper A Minimalist Program for Linguistic Theory. That paper attempted to reduce the complexity of what is in the Narrow Faculty of Language (forgive the anachronism) by removing D-Structure and S-structure, by creating a version of the Binding Theory that held of essentially semantic representations, and by arguing that restrictions on syntactic dependencies were a side effect of restrictions that are likely to hold of computational systems in general. It also proposed reducing cross-linguistic variation to what has to be learned anyway, the morphological properties of lexical items, following a much earlier idea of my colleague Hagit Borer’s. The approach within Minimalist syntax since then has generally followed this broad path, attempting to build a theory of the Narrow Faculty of Language that is much “reduced”.
Reduction: There are two types of reduction we see over the history of minimalism. The first is what leads Haspelmath to wonder whether Norbert Hornstein (!!!) is an ex-generative grammarian, and it involves seeking the explanation for aspects of syntax outside of the syntactic system itself. The second is, I think, what leads to his puzzlement.
Type 1 reduction: The first type concerns the description and explanation of phenomena. Haspelmath points to a paper by Julie Legate which argues that there is nothing in the Narrow Faculty of Language that constrains the way that agents and themes operate in passives. Legate concludes that the promotion of themes and the demotion of agents are independent factors, so that the Narrow Faculty of language doesn’t have constrain their interaction. This is good, from a minimalist point of view, as it means that what is posited as part of the Narrow Faculty of Language is reduced tout court.
A slightly different example is Amy-Rose Deal’s work on ergativity, also quoted by Haspelmath. In her 2016 paper, Deal argues for a syntactic analysis of a person split in Nez Perce case assignment (basically 1st and 2nd person get nominative as opposed to ergative case). To reconcile this with other work which accounts for the same pattern in other languages through morphological rule, as opposed to syntactic structure, Deal suggests that there is something extra-grammatical at the heart of person splits. This is, as she notes, a possibility in minimalist syntactic theory, again reducing what is posited as part of the Narrow Faculty of Language, though in this case, unlike Legate’s conclusions about Passive, there is still something doing the job of constraining the typology, but that something is outside of the Narrow Faculty of Language.
Aside: Personally, I think that an alternative, where both the morphology and syntax are a side effect of some deeper syntactic fact, is still worth considering and I’ve never understood why, under a functionalist account, we don’t find splits between first and second persons, but I’m no expert in this area, and Deal’s proposal is certainly not inconsistent with Minimalist syntax.
In any event, a quick glance at both Legate’s and Deal’s papers shows a fair amount of appeal to language specific mechanisms of the kind Haspelmath finds puzzling, a point I return to below.
A final example of attempted reduction comes from my own work with Peter Svenonius on bound variable anaphora, where we are more explicit about how primitives that seem to be in the Narrow Faculty of Language may actually be due to what Chomsky in his 2005 paper calls Third Factor properties: these Third Factor properties are not part of the Narrow Faculty of Language nor are they attributable to the information in the data a child learning their language is exposed to. In our 2015 paper, Peter and I proposed a minimalist system to capture the constraints on when a pronoun can, and cannot, be bound by a quantifier, and we then subjected the various primitives of that system to the question of what language external systems might be responsible for them. We suggested that, for example, the notion of “phase” in syntax could be seen as an instantiation of the periodicity of computational systems more generally (Strogatz and Stewart 1993). We also suggested that the notion of spellout of syntactic copies could be connected to general cognitive mechanisms for keeping track of single objects in different temporal or spatial locations (Leslie et al 1998). The idea is that these properties are part of the Broad Faculty of Language but are obligatorily coopted by the Narrow one. On this perspective the Narrow Faculty of Language is basically a specification of which cognitive capacities are co-opted by language and how they are co-opted.
Type 2 reduction: Now to the second type of reduction. Imagine we have a phenomenon that appears to require a great deal of rich structure in the Narrow Faculty, say the features responsible for pronominal systems in languages of the world. In such a case we can try to reduce the amount of structure and content of the Narrow Faculty of Language by improving the theory itself. This means making the primitives of the theory fewer and more abstract, but with wider empirical reach. This is the point made by Kayne in the quote Haspelmath gives:
“Cross-linguistically valid primitive syntactic notions will almost certainly turn out to be much finer-grained than any that Haspelmath had in mind.” (Kayne 2013: 136, n. 20)
My go-to example here is my colleague Daniel Harbour’s theory of person and number features. Harbour develops an approach to explaining the typology of person-number systems in pronouns that reduces the rich range of types of system to the interaction of three features. His crucial insight is that these features are functions which can take other features as their arguments. This allows him to derive the empirical effects of the highly structured feature geometries that had been used by researchers like Ritter, Harley, Cowper and others to capture pronoun typologies. His system is much sparser in what it posits, but it has the same (in fact, he argues, better) empirical coverage.
Another example is Chomsky’s reduction of movement and phrase structure to a single mechanism. Within GB and early Minimalism the two were always assumed to be distinct aspects of syntax and so the theory claimed that the Narrow Faculty of Language included two distinct operations. Chomsky’s 2004 simplification of Merge in his paper Beyond Explanatory Adequacy (apologies, can’t find a link) meant that the same mechanism was responsible for both types of structure, so that the specification of what is in the Narrow Faculty is reduced.
This second approach to reduction doesn’t remove richness by attributing it to other aspects of cognition, it rather improves the theory itself. It leads inevitably to high degrees of abstraction. The complexity of the empirical phenomena is argued to arise from behaviour of simple elements interacting. Crucially, these simple elements do not directly correspond to aspects of the observable phenomena. To the extent we see the same elements involved in the explanation of very distinct phenomena, we have a kind of explanation that relies on abstraction.
Abstraction: One thing I’ve noticed in my (fun but sometimes frustrating) Twitter conversations with Martin Haspelmath, Adele Goldberg and others is an argument that goes as follows:
“…but look at all this ridiculous stuff you put in your trees. Just no!”
I think of this as the Argument from Allergy to Abstraction: the trees are too complex in structure, they have too many things in them that seem to come from nowhere, and far too many null things. It’s not reasonable to think that all that complexity is built in to syntax.
But abstraction is a valuable mode of explanation.
Trees are, of course, not the primitives of the theory. A complex tree can be built out of simple things. As I pointed out in Language Unlimited, the fractal shapes of a Romanesco cauliflower can be given by a simple equation. The whole point of generative grammars as a formalism is that they generate unbounded structures from some very minimal units and modes of combination. That’s what makes them good models for syntax. Simpler syntax (to steal a phrase) is not about making the trees simple, it’s about making the system that generates them simple. Syntax is the system, not the output.
Lets assume that the trees aren’t the issue then. What seems to exercise Haspelmath is the categories and operations, and this is the question we started with.
Haspelmath’s Puzzlement: Haspelmath is puzzled by why generative syntacticians, even those like Legate and Deal who have rejected the innateness of certain properties by following the first type of reduction, quite happily pepper their analyses with categories like DP and vP, and with dotted lines expressing movement or long distance Agree dependencies. What justifies these? The only justification Haspelmath sees for using such categories and relations in syntactic analysis is that they are innate. But those same individuals seem to have a cavalier attitude to innateness in general.
Placeholders for a better understanding: I’ve struggled for a while to make sense of Haspelmath’s worry here. I think it comes down to how abstraction requires you to be comfortable with theoretical uncertainty and change. If your categories are abstract, they are grounded by just their explanatory capacity, and since understanding is always changing, you’d better be prepared for your abstract categories to change too.
From my perspective (and I think the perspective of most if not all generative theoretical syntacticians), DP, vP, Agree and all the rest are then very likely to be placeholders for a better future theory. The analyses that use them are not meant to be the final word. They are stepping stones which have taken us further than we were, but there’s a long way to go still.
Perhaps vP (or D, or even Merge) will indeed end up being a necessary component of the Narrow Faculty of Language. Perhaps, though, it will end up being dissolved into a number of yet more abstract primitives. Perhaps it will end up being the interaction of some third factor property with the syntax. Perhaps it will just be plain wrong, to be replaced by a totally different view of categories, just as phrase structure rules have vanished from Minimalism. It doesn’t matter right now though. It serves as an anchor for the analysis, a stable point that the relevant generalizations can hook on to, and a crystallization of a set of claims that can be challenged. We hope, of course, that our theoretical posits are the right ones, but realistically they’re surely not.
This is the point of theory: it gives us a momentary platform which we can use to find the next, and then the next steps, or which we can dismantle because it turned out to be wrong. It improves understanding, but gives no final answer (at least not at the state we are at in linguistics). I think generativists are generally comfortable with that kind of approach to theory because a major mode of explanation relies on abstract theory. The concepts we work with are good enough to enhance our understanding, and drive new empirical discoveries, and open up new questions to be answered, new theories to be developed.
Haspelmath asks how generativists can “continue to work with the assumption of uniform building blocks, if these are not innate”.
The answer is, as Gillian Ramchand, José-Luis Mendívil-Giró, Radek Šimík, and Dennis Ott all said in one way or another in the quotes in Haspelmath’s blog: we don’t really care about DPs or vPs or whatever being innate. The theory (or family of theories) we use are our best guesses, but we’re happy when what we thought had to be in the Narrow Faculty of Language can be explained by some third factor, (as long as that explanation is at least as empirically adequate as the one we had before).
My answer to the question “Are generative grammarians abandoning innateness?” is: we’ve continually been abandoning (and adopting, and abandoning again) particular suggestions for what is in, or is not in, the Narrow Faculty of language. That’s the nature of the field and it’s always been so.
Chomsky, back in 1980, writes this in response to the philosopher Hilary Putnam, who is complaining about Chomsky’s “Innateness Hypothesis”
“For just this reason I have never used the phrase “the innateness hypothesis” in putting forth my views, nor am I committed to any particular version of whatever Putnam has in mind in using this phrase (which, to my knowledge, is his and his alone) as a point of doctrine. As a general principle, I am committed only to the “open-mindedness hypothesis” with regard to the genetically determined initial state for language learning (call it S0), and I am committed to particular explanatory hypotheses about S0 to the extent that they seem credible and empirically supported.”
This has always been the attitude of generative linguists: we adopt particular hypotheses as long as they do explanatory work for us, and if it seems they have no explanation outside of the Narrow Faculty of Language (what Chomsky calls S0 in the quote), that’s where we put them. If they are superseded by alternative hypotheses that are Third Factor, that’s all to the good. This is why the individuals Haspelmath mentions in his post are not ex-generativists, and it’s why they work with those theoretical ideas which seem to them to be “credible and empirically supported”
That LSA Letter
I’ve had a couple of senior colleagues ask me why I signed the LSA letter, one curious, one censorious. I’ve also had a number of personal emails from people I don’t know, some saying that my signing the letter was shameful, etc. I thought I should make brief summary of the reasons why I signed the letter, though I usually don’t blog about things that aren’t syntax and related stuff.
There’s also a useful blog by Barbara Partee which takes a different view on these matters.
I was sent the letter before it appeared publicly, and I thought hard about signing it. There were a number of arguments in the letter that I didn’t find compelling, but there were three points in particular that convinced me that there were misrepresentations of fact in the tweets and that those led to a potential for harm.
I don’t know Professor Pinker personally, so my signing of the letter was purely based on the nature of the tweets I discuss below. People can hold and defend whatever views they like, but misrepresenting positions or facts in service of those views, and thereby creating potential harm, isn’t consistent with the highest standards of professional responsibility.
The first argument was the tweet: “Data: police don’t shoot blacks disproportionately. Problem: not race but too many police shootings”. If you look at the article, it very clearly states that race is the problem: “The data is unequivocal. Police killings are a race problem: African-Americans are being killed disproportionately and by a wide margin.” The tweet is misrepresenting the claims in the article. It could have said: “Data: proportion of whites shot by police who stop them is the same as the proportion of blacks. Problem: structural racism means police stop black people disproportionately, and so kill them disproportionally.” That’s what the article says, and it’s the opposite of what the tweet says: police do shoot black men disproportionately and the problem is race. Barbara Partee in her blog suggests that this was just sloppy, but as far as I can tell the tweet was never corrected or supplemented even when challenged in responses to the original post. And uncorrected sloppiness is irresponsible in this area, as it has the potential to provide succour to those who espouse racist views.
The second was “Every geneticist knows that the ‘race doesn’t exist’ dogma is a convenient PC ¼ truth.” This is untrue even if you forgive the hyperbole. Academic societies of geneticists “challenge[s] the traditional concept of different races of humans as biologically separate and distinct” because genetic variance within populations that are socially classed as racial groups is far wider than that between such populations, and so there’s no meaningful way to establish the boundaries that have been socially constructed via clear groupings of genetic markers, so “race itself is a social construct”. Stephen Rose back in a lecture on Genetics and Society in 2002 summarized the state of the field as “The consensus view among population geneticists and biological anthropologists is that the concept of “race” to indicate analytically distinct subgroups of the human race is biologically meaningless,” and the American Association of Physical Anthropology makes the same point in their statement of 1996 (“Pure races, in the sense of genetically homogenous populations, do not exist in the human species”), since updated. The consenus was, then, the polar opposite of the tweet’s claim. The tweet wasn’t about race as a social category, given the content of the article embedded in it; it was referring to race as a biological category. Though this tweet was from 2013, it misrepresented the facts then, and the potential harms such views cause remain central to the everyday experience of racism now. The tweet was used as a supporting argument in a piece in Medium just last year (I won’t link it here but a google search will take you there if you are interested) by a researcher who was arguing for correlations between race and IQ, so such statements can be harmful (as well as false) years after they are made.
The third was the misrepresentation of Bobo’s position in his interview as reflecting cautious optimism on race relations, plus the harmful timing of the tweet. Bobo throughout the interview makes it clear that things are pretty bad because of systemic racism (e.g. “devaluing of black life, sadly, is a part of the American cultural fabric. Not as extreme as it used to be, but still very clear and very deeply rooted”). The whole tone of Bobo’s interview is not cautiously optimistic – it’s pessimistic given the deep-seated racism and political structures of the US – his note of optimism is: “we’re in a deeply troubling moment. But I am going to remain guardedly optimistic that hopefully the higher angels of our nature win out in what is a really frightening coalescence of circumstances”. That is emphatically not him reflecting with cautious optimism on race relations in the context of the killings of black men, as the tweet says. Further, the tweet was spectacularly awfully timed to be right in the middle of BLM protests (3rd June 2020) – like saying, calm down everybody, it’s not as bad as you think. Again we have a coalescence of misrepresentation and potential harm.
I concluded that those tweets had misrepresented positions in a way that both has potential negative effects on black people, and provided statements that are potentially helpful to racists. That is, the misrepresentations were harmful. My judgment was that at least the LSA should consider the question of whether that was consistent with LSA Fellows’ responsibilities to uphold the highest professional standards and come to their own conclusion. That’s why I signed the letter, while recognizing that it was, of course, a blunt instrument.
This isn’t an issue of free speech, which seems to be how it has been taken by many. For me, at least, Pinker’s views are absolutely not at issue. It’s about misrepresentation and harm. Because of this, I’m unconvinced that the LSA letter will have a chilling effect on scholars, a concern that some have raised. Tweets like the ones discussed here (and other similar pronouncements) do, though, exert a chilling effect on (potential) black scholars. Racist structures and racist attitudes in society and academia have meant that many black scholars either haven’t felt welcome in academia and have made other choices or have left it. Any resulting action from this letter may make it clear to black scholars that the LSA is sensitive to the impact that tweets of this sort have on maintaining structures that we all should be attempting to dismantle.
Invented Languages and the Science of the Mind
This post was abridged and reblogged from BBC Science Focus.
Hildegard von Bingen was something of a medieval genius. She founded and was Abbess of a convent at Rubensberg in Germany, she wrote ethereally beautiful music, she was an amazing artist (one of the first to draw the visual effects of migraines), and she invented her own language.

Hildegard von BingenSource: Miniatur aus dem Rupertsberger Codex des Liber Scivias. Public Domain
The language she constructed, Lingua Ignota (Latin for “Unknown Language”) appears to be a secret, mystical language. It was partly built on the grammar of languages Hildegard already knew, but with her usual creativity, she invented over a thousand words, and a script consisting of 23 symbols.
The Lardil, an Aboriginal people of Northern Australia, as well as their day-to-day language, also used a special ritual language, restricted to the adult men. This language, Damin, is the only known language outside of sub-Saharan Africa to incorporate click sounds into its words.
In fact, the sounds of Damin are a creative extension of the sounds of Lardil, showing a deep level of knowledge of how linguistic sounds are made. The Lardil say that Damin was invented in Dreamtime. It certainly shows signs of having been constructed, with careful thought about how it is structured.
While most languages have emerged and changed naturally in human societies, some languages are constructed by human beings. Hildegard’s Lingua Ignota was created for religious purposes and Damin for social and ritual reasons.
More recent constructed languages (or ‘conlangs’), like the Elvish languages J. R. R Tolkien developed for The Lord of the Rings, or the Dothraki and High Valyrian languages David Peterson created for the TV series Game of Thrones, were developed for artistic or commercial reasons. However, constructed languages can also be used in science to understand the nature of natural languages.
There’s a long-standing controversy amongst linguists: are human minds set up to learn language in a particular way, or do we learn languages just because we are highly intelligent creatures? To put it another way, is there something special about language-learning that distinguishes it from other kinds of learning?
Constructed languages have been used to probe this question. There are some striking results which suggest there is indeed something special about language-learning.
One example where constructed languages have been used scientifically is to explore the difference between grammatical words (like the, be, and, of, a) and words that convey the essence of what you’re talking about (like alligator, intelligent, enthral, dance).
This difference is found in language after language. Generally, grammatical words are very short, they tend to be simple syllables, and they are frequent. They signal grammatical ideas, like definiteness and tense. Core meaning words tend to be longer, more complex in their syllable structure, each one is less frequent.
If you look at a list of English words organised by frequency, you have to go down to number 19 before you get to a core meaning word (say), and the next (make) is at 45. The examples of grammatical words I gave above (the, be, and, of, a) are in fact the five most frequent words in English.
One of the properties of grammatical words is that they don’t have fixed positions in a sentence. If you look at the sentence you’ve just read, you can see grammatical words interspersed quite randomly through it. Here it is repeated with those words in bold.
“One of the properties of grammatical words is that they don’t have fixed positions in a sentence.”
Depending on the language, grammatical words appear either randomly, like in this sentence, or they appear fairly consistently either immediately before or immediately after core meaning words, like in this example from Scottish Gaelic.
Cha do bhuail am balach earchdail an cat gu cruaidh
Not past hit the boy handsome the cat hard
which translates as ‘the handsome boy didn’t hit the cat hard’. Here the short grammatical words in bold come immediately before longer core meaning words.

Anduril, a prop sword from Lord of the Rings engraved in ElvishSource: Peter Macdiarmid/Getty Images
The researchers Iga Nowak, formerly in Glasgow, and Giosuè Baggio in Trondheim, taught different groups of children constructed languages. In some of these languages, the short frequent words had fixed positions, in others, the positions were freer, mimicking what happens in real languages.
Nowak and Baggio reasoned that, if children came with an unconsciousexpectation about how grammatical words worked, they should find it harder to learn constructed languages where the short frequent words had fixed positions.
Human languages in general don’t work like this, so if children were using a specialised language learning system, they should find such languages difficult to learn.
Nowak and Baggio ran the same experiment with adults. Their idea here was that adults would be able to use other strategies, like counting, and should be good with languages that put short frequent words in particular positions. The children, on the other hand, would have to rely on their innate linguistic sense, if they had any!
The experiments turned out as Nowak and Baggio expected. The children were not capable of learning the artificial languages where the short frequent words appeared in fixed positions, but they were good at learning the other kinds of languages.
The adults, on the other hand, were good at learning the artificial languages that the children were bad at.
Using constructed languages scientifically, Nowak and Baggio have added to evidence that children may come to language learning with unconscious expectations about what the system they are learning should be like. The results are consistent with the idea that a system with grammatical words in fixed positions in sentences is not a natural language, as far as children are concerned.article continues after advertisement
Human beings love to play with language. Many, over the centuries, have constructed languages to express deep religious, social, artistic and philosophical ideas. Science, too, is a kind of play: we try out different ideas, see how they work out, and learn about the world as we do so. It’s not surprising then that constructed languages have recently become part of the way linguists and psychologists investigate our most human trait, language.
How the limits of the mind shape human language
(Rebogged from The Conversation)

When we speak, our sentences emerge as a flowing stream of sound. Unless we are really annoyed, We. Don’t. Speak. One. Word. At. A. Time. But this property of speech is not how language itself is organised. Sentences consist of words: discrete units of meaning and linguistic form that we can combine in myriad ways to make sentences. This disconnect between speech and language raises a problem. How do children, at an incredibly young age, learn the discrete units of their languages from the messy sound waves they hear?
Over the past few decades, psycholinguists have shown that children are “intuitive statisticians”, able to detect patterns of frequency in sound. The sequence of sounds rktr is much rarer than intr. This means it is more likely that intr could occur inside a word (interesting, for example), while rktr is likely to span two words (dark tree). The patterns that children can be shown to subconsciously detect might help them figure out where one word begins and another ends.
One of the intriguing findings of this work is that other species are also able to track how frequent certain sound combinations are, just like human children can. In fact, it turns out that that we’re actually worse at picking out certain patterns of sound than other animals are.
Linguistic rats
One of the major arguments in my new book, Language Unlimited, is the almost paradoxical idea that our linguistic powers can come from the limits of the human mind, and that these limits shape the structure of the thousands of languages we see around the world.
One striking argument for this comes from work carried out by researchers led by Juan Toro in Barcelona over the past decade. Toro’s team investigatedwhether children learned linguistic patterns involving consonants better than those involving vowels, and vice versa.

They showed that children quite easily learned a pattern of nonsense words that all followed the same basic shape: you have some consonant, then a particular vowel (say a), followed by another consonant, that same vowel, yet one more consonant, and finally a different vowel (say e). Words that follow this pattern would be dabale, litino, nuduto, while those that break it are dutone, bitado and tulabe. Toro’s team tested 11 month old babies, and found that the kids learned the pattern pretty well.
But when the pattern involved changes to consonants as opposed to vowels, the children just didn’t learn it. When they were presented with words like dadeno, bobine, and lulibo, which have the same first and second consonant but a different third one, the children didn’t see this as a rule. Human children found it far easier to detect a general pattern involving vowels than one involving consonants.
The team also tested rats. The brains of rats are known to detect and processdifferences between vowels and consonants. The twist is that the rat brains were too good: the rats learned both the vowel rule and the consonant rule easily.
Children, unlike rats, seem to be biased towards noticing certain patterns involving vowels and against ones involving consonants. Rats, in contrast, look for patterns in the data of any sort. They aren’t limited in the patterns they detect, and, so they generalise rules about syllables that are invisible to human babies.

This bias in how our minds are set up has, it seems, influenced the structure of actual languages.
Impossible languages
We can see this by looking at the Semitic languages, a family that includes Hebrew, Arabic, Amharic and Tigrinya. These languages have a special way of organising their words, built around a system where each word can be defined (more or less) by its consonants, but the vowels change to tell you something about the grammar.
For example, the Modern Hebrew word for “to guard” is really just the three consonant sounds sh-m-r. To say, “I guarded”, you put the vowels a-a in the middle of the consonants, and add a special suffix, giving shamarti. To say “I will guard”, you put in completely different vowels, in this case e-o and you signify that it’s “I” doing the guarding with a prefixed glottal stop giving `eshmor. The three consonants sh-m-r are stable, but the vowels change to make past or future tense.
We can also see this a bit in a language like English. The present tense of the verb “to ring” is just ring. The past is, however, rang, and you use yet a different form in The bell has now been rung. Same consonants (r-ng), but different vowels.
Our particularly human bias to store patterns of consonants as words may underpin this kind of grammatical system. We can learn grammatical rules that involve changing the vowels easily, so we find languages where this happens quite commonly. Some languages, like the Semitic ones, make enormous use of this. But imagine a language that is the reverse of Semitic: the words are fundamentally patterns of vowels, and the grammar is done by changing the consonants around the vowels. Linguists have never found a language that works like this.
We could invent a language that worked like this, but, if Toro’s results hold up, it would be impossible for a child to learn naturally. Consonants anchor words, not vowels. This suggests that our particularly human brains are biased towards certain kinds of linguistic patterns, but not towards other equally possible ones, and that this has had a profound effect on the languages we see across the world.
Charles Darwin once said that human linguistic abilities are different from those of other species because of the higher development of our “mental powers”. The evidence today suggests it is actually because we have different kinds of mental powers. We don’t just have more oomph than other species, we have different oomph.
Where Do the Rules of Grammar Come From?
Reblogged from Psychology Today

When we speak our native language we unconsciously follow certain rules. These rules are different in different languages. For example, if I want to talk about a particular collection of oranges, in English I say
Those three big oranges
In Thai, however, I’d say
Sôm jàj sǎam-lûuk nán
This is, literally, Oranges big three those, the reverse of the English order. Both English and Thai are pretty strict about this, and if you mess up the order, speakers will say that you’re not speaking the language fluently.
The rule of course doesn’t mention particular words, like big, or nán, it applies to whole classes of words. These classes are what linguists call grammatical categories: things like Noun, Verb, Adjective and less familiar ones like Numeral (for words like three or five) and Demonstrative (the term linguists use for words like this and those). Adjectives, Numerals and Demonstratives give extra information about the noun, and linguists call these words modifiers. The rules of grammar tell us the order of these whole classes of words.
Where do these rules come from? The common-sense answer is that we learn them: as English speakers grow up, they hear the people around them saying many, many sentences, and from these they generalize the English order; Thai speakers, hearing Thai sentences, generalize the opposite order (and English-Thai bilinguals get both). That’s why, if you present an English or Thai speaker with the wrong order, they’ll immediately detect something is wrong.
But this common-sense answer raises an interesting puzzle. The rules in English, from this kind of perspective, look roughly as follows:
The normal order of words that modify nouns is:
- Demonstratives precede Numerals, Adjectives and Nouns
- Numerals precede Adjectives and Nouns
- Adjectives precede Nouns
There are 24 possible ways of ordering the four grammatical categories. If the order in different languages is simply a result of speakers learning their languages, then we’d expect to see all 24 possibilities available in languages around the world. Everything else being equal, we’d also expect the various orders to be pretty much equally common.
However, in the 1960s, the comparative linguist, Joseph Greenberg, looked at a bunch of unrelated languages and found that this simply wasn’t true. Some orders were much more common than others, and some orders simply didn’t seem to be present in languages at all. More recent work by Matthew Dryer looking at a much larger collection of languages has confirmed Greenberg’s original finding. It turns out that the English and Thai orders are by far the most common, while other orders—such as that of Kîîtharaka, a Bantu language spoken in Kenya, in which you say something like Oranges those three big—are much rarer. Dryer, like Greenberg, found that some orders just didn’t exist at all.article continues after advertisement
This is a surprise if speakers learn the order of words from what they hear (which they surely do), and each order is just as learnable as the others. It suggests either that some historical accident has led to certain orders being more frequent in the world’s languages, or, alternatively, that the human mind somehow prefers some orders to others, so these are the ones that, over time, end up being more common.
To test this, my colleagues Jennifer Culbertson, Alexander Martin, Klaus Abels, and I are running a series of experiments. In these, we teach people an invented language, with specially designed words that are easily learnable, whether the native language of our speakers is English, Thai or Kîîtharaka. We call this language Nápíjò and we tell the people who are doing the experiments that it’s a language spoken by about 10,000 people in rural South-East Asia. This is to make Nápíjò as real as possible to people.
Though we keep the words in Nápíjò the same for all our speakers, we mess around with the order of words. When we test English speakers, we teach them a version of Nápíjò with the Adjectives, Numerals and Demonstratives after the Noun (unlike in English); we also teach Nápíjò to Thai speakers, but we use a version with all these classes of words before the noun (unlike in Thai).
The idea behind the experiments is this: We teach speakers some Nápíjò, enough so they know the order of the noun and the modifiers, but not enough so they know how the modifiers are ordered with respect to each other. Then we have them guess the order of the modifiers. Their guesses tell us about what kind of grammar rule they are learning, and the pattern of the guesses should tell us something about whether that grammar rule is coming from their native language, or from something deeper in their minds.article continues after advertisement
In the experiments, we show speakers pictures of various situations–for example, a girl pointing to a collection of feathers—and we give our speakers the Nápíjò phrase that corresponds to these. The Nápíjò phrases that the participants hear for the diagrams below would correspond to red feather on the left and to that feather, on the right. We give the speakers enough examples so that they learn the pattern.

Red Feather and That Feather
Once the participants in the experiment have learned the pattern, we then test to see what they would do when you have two modifiers: for example, an Adjective and a Numeral, or a Demonstrative and an Adjective. We have of course, somewhat evilly, not given our speakers any clue as to what they should do. They have to guess!
Now, if the speakers are simply using the order of words from their native language, then they should be more likely to guess that the order of words in Nápíjò would follow it. That’s not, however, what English or Thai speakers do.
For a picture that shows a girl pointing at “those red feathers”, English speakers don’t guess that the Nápíjò order is Feathers those red, which would keep the English order of modifiers but is very rare cross-linguistically when the noun comes first. Instead, they are far more likely to go for Feathers red those, which is very common cross-linguistically (it is the Thai order), but is definitely not the English order of the modifiers.article continues after advertisement
Thai speakers, similarly, didn’t keep the Thai order of Adjective and Demonstrative. Instead, they were more likely to guess the English order, which, when the noun comes last (as it did for them), is very common across languages.
This suggests that the patterns of language types discovered by Greenberg, and put on an even firmer footing by Dryer, may not be the result of chance or of history. Rather the human mind may have an inherent bias towards certain word orders over others.
Our experiments are not quite finished, however. Both English and Thai speakers use patterns in their native language that are very common in languages generally. But what would happen if we tested speakers of one of the very rare patterns? Would even they still guess that Nápíjò uses an order which is more frequent in languages of the world?

The U.K. team with local team member Patrick Kanampiu
To find out, we’ve just arrived in Kenya, where we will do a final set of experiments. We’ll test speakers of Kîîtharaka (where the order is roughly Oranges those three big). We’ll test them on a version of Nápíjò where the noun comes last, unlike in their own language. If they behave just like Thai speakers, who we also taught a version of Nápíjò where the noun comes last, we will have really strong evidence that the linguistic nature of the human mind shapes the rules we learn. Who knows though, science is, after all, a risky business!
(Many thanks to my co-researchers, Jenny Culbertson (Principal Investigator), Alexander Martin and Klaus Abels for comments, and to the UK Economic and Social Research Council for funding this research)
What Invented Languages Can Tell Us About Human Language

(Reblogged from Psychology Today)
Hash yer dothrae chek asshekh?
This is how you ask someone how they are in Dothraki, one of the languages David Peterson invented for the phenomenally successful Game of Thrones series. It is an idiom in Peterson’s constructed language, meaning, roughly “Do you ride well today?” It captures the importance of horse-riding to the imaginary warriors of the land of Essos in the series.
Invented, or constructed languages, are definitely coming into their own. When I was a young nerd, about the age of eleven or twelve, I used to make up languages. Not very good ones, as I knew almost nothing then about how languages work. I just invented words that I thought looked cool on the page (lots of xs and qs!), and used these in place of English words.
I wasn’t the only person that did this. J.R.R Tolkien wrote an essay with the alluring title of A Secret Vice, all about his love of creating languages: their words, their sounds, their grammar and their history, and the internet has created whole communities of ‘conlangers’, sharing their love of invented languages, as Arika Okrent documents in her book In the Land of Invented Languages.
For the teenage me, what was fascinating was how creating a language opened up worlds of the imagination and how it allowed me to create my own worlds. I guess it’s not surprising that I eventually ended up doing a PhD in Linguistics. Those early experiments with inventing languages made me want to understand how real languages work. So I stopped creating my own languages and, over the last three decades, researched how Gaelic, Kiowa, Hawaiian, Kiitharaka, and many other languages work.
A few years back, however, I was asked by a TV producer to create some languages for a TV series, Beowulf, and that reinvigorated my interest in something I hadn’t done since my early 20s. It also made me realise that thinking about how an invented language could work actually helps us to tackle some quite deep questions in both linguistics and in the psychology of language.
To see this, let me invent a small language for you now.
This is how you say “Here’s a cat.” in this language:
Huna lo.
and this is how you say “The cat is big.”
Huna shin mek.
This is how you say “Here’s a kitten.”
Tehili lo.
Ok. Your turn. How do you say “The kitten is big.”?
Easy enough, right? It’s:
Tehili shin mek.
You’ve spotted a pattern, and generalized that pattern to a new meaning.

Ok, now we can get a little bit more complicated. To say that the cat’s kitten is big, you say
Tehili ga huna shin mek.
That’s it. Now let’s see how well you’ve learned the language. If I tell you that the word for “tail” is loik, how do you think you’d say: “The cat’s tail is big.”?
Well, if “The cat’s kitten is big” is Tehili ga huna shin mek, you might guess,
Loik ga huna shin mek
Well done (or Mizi mashi as they say in this language!). You’ve learned the words. You’ve also learned some of the grammar of the language: where to put the words. We’re going to push that a little further, and I’ll show you how inventing a language like this can cast interesting facts about human languages into new light.
The fragments of the constructed language you’ve learned so far have come from seeing the patterns between sound (well, actually written words) and meaning. You learned that cat is huna and kitten is tehili by seeing them side by side in sentences meaning “Here’s a cat.” and “Here’s a kitten.”. You learned that the possessive meaning between cat and kitten (or cat and tail) is signified by putting the word for what is possessed first, followed by the word ga, then the word for the possessor.
This is a little like how linguists begin to find out how a language that is new to them works. I’ve learned how many languages work in this way: by consulting with native speakers, finding out the basic words, seeing how the speaker expresses whole sentences, and figuring out what the patterns are that connect the words and the meanings. This technique allows you to discover how a language functions: what its sounds and words are, and how the words come together to make up the meanings of sentences.
Now, how do you think you’d say: “The cat’s kitten’s tail is big.”?
You’d probably guess that it would be:
Loik ga tehili ga huna shin mek.
The reasoning works a little like this: if the cat’s kitten is tehili ga huna, and the kitten is the possessor of the tail, then the cat’s kitten’s tail should be loik ga tehili ga huna. Similarly, if the word for “tip” is mahia, then you should be able to say
Mahia ga loik ga tehili ga huna shin mek.
That’s a pretty reasonable assumption. In fact, it’s how many languages work. But say I tell you that there’s a rule in my invented language: there’s a maximum of two gas allowed. So you can say “The cat’s kitten’s tail is big.”, but you can’t say “The cat’s kitten’s tail’s tip is big.” My language imposes a numerical limit. Two is ok, but three is just not allowed.
Would you be surprised to know that we don’t know of a single real language in the whole world that works like this? Languages just don’t use specific numbers in their grammatical rules.
I’ve used this invented language to show you what real languages don’t ever do. I’ll come back in the next blog to how we can use invented languages to understand what real languages can’t do.
We can see the same property of language in other areas too. Think of the child’s nursery rhyme about Jack’s house. It starts off with This is the house that Jack built. In this sentence we’re talking about a house, and we’re saying something about it: Jack built it. The dramatic tension then builds up, and we meet … the malt!
This is the malt that lay in the house that Jack built.
Now we’re talking about malt (which is what you get when you soak grain, let it germinate, then quickly dry it with hot air). We’re saying something about the malt: it lay in the house that Jack built. We’ve said something about the house (Jack built it) and something about the malt (it lay in the house). English allows us to combine all this into one sentence. If English were like my invented language, we’d stop. There would be a restriction that you can’t do this more than twice, so the poor rat, who comes next in the story, would go hungry.
This is rat that ate the malt that lay in the house that Jack built.
But English doesn’t work like my invented language. In English, we can keep on doing this same grammatical trick, eventually ending up with the whole story, using one sentence.
This is the farmer sowing his corn,
That kept the cock that crow’d in the morn,
That waked the priest all shaven and shorn,
That married the man all tatter’d and torn,
That kissed the maiden all forlorn,
That milk’d the cow with the crumpled horn,
That tossed the dog,
That worried the cat,
That killed the rat,
That ate the malt
That lay in the house that Jack built.
This is actually a very strange, and very persistent property of all human languages we know of: the rules of language can’t count to specific numbers. Once you do something once, you either stop, or you can go on without limit.
What makes this particularly intriguing is that there are other psychological abilities that are restricted to particular numbers. For example, humans (and other animals) can immediately determine the exact number of small amounts of things, up to 4 in fact. If you see a picture with either two or three dots, randomly distributed, you know immediately the exact number of dots without counting. In contrast, if you see a picture with five or six dots randomly distributed, you actually have to count them to know the exact number.
The ability to immediately know exact amounts of small numbers of things is called subitizing. Psychologists have shown that we do it in seeing, hearing and feeling things. We can immediately perceive the number if it’s under 4, but not if it’s over. In fact, even people who have certain kinds of brain damage that makes counting impossible for them still have the ability to subitize: they know immediately how many objects they are perceiving, as long as it’s fewer than 4.
But languages don’t do this. Some languages do restrict a rule so it can only apply once, but if it can apply more than once, it can apply an unlimited number of times.
This property makes language quite distinct from many other areas of our mental lives. It also raises an interesting question about how our minds generalize experience when it comes to language.
A child acquiring language will rarely hear more than two possessors, as I document in my forthcoming book Language Unlimited, following work by Avery Andrews. Why then do children not simply construct a rule based on what they experience? Why don’t at least some of them decide that the language they are learning limits the number of possessors to two, or three, like my invented language does?
Children’s ability to subitize should provide them with a psychological ability to use as a limit. They hear a maximum of three possessors, so why don’t they decide their language only allows three possessors. But children don’t do this, and no language we know of has such a limit.
Though our languages are unlimited, our minds, somewhat paradoxically, are tightly constrained in how they generalize from our experiences as we learn language as infants. This suggests that the human mind is structured in advance of experience, and it generalizes from different experiences differently, and idea which goes against a prevailing view in neurosciencethat we apply the same kinds of generalizing capacity to all of our experiences.

Inventing Languages – how to teach linguistics to school students
Last week was a busy week at Queen Mary Linguistics. Coppe van Urk and I ran a week long summer school aimed at Year 10 students from schools in East and South London on Constructing a Language. We were brilliantly assisted by two student ambassadors (Dina and Sharika) who, although their degrees are in literature rather than linguistics, are clearly linguists at heart! We spent about 20 hours with the students, and Sharika and Dina gave them a break from us and took them for lunch. The idea behind the summer school, which was funded as part of Queen Mary’s Widening Participation scheme, was to introduce some linguistics into the experience of school students.
In the summer school, we talked about sounds (phonetics), syllable structures (phonology), how words change for grammatical number and tense (morphology), and word order, agreement and case (syntax). We did this mainly through showing the students examples of invented languages (Tolkien’s Sindarin, Peterson‘s Dothraki, Okrand’s Klingon, my own Warig, Nolan‘s Parseltongue, and various others). Coppe and I had to do some quick fieldwork on these languages (using the internet as our consultant!) to get examples of the kinds of sounds and structures we were after. The very first day saw the students creating a cacophony of uvular stops, gargling on velars, and hissing out pharyngeal fricatives. One spooky, and somewhat spine-chilling, moment was the entire class, in chorus, eerily whispering Harry Potter’s Parseltongue injunction to the snake attacking Seumas:
leave.2sg.erg him go.2sg.abs away
“Leave him! Go away!”
During the ensuing five days, the students invented their own sound systems and syllable structures, their own morphological and syntactic rules. As well as giving them examples from Constructed Languages, we also snuck in examples of natural languages which did weird things (paucals, remote pasts, rare word orders, highly complex (polysynthetic) word structures). Francis Nolan, Professor of Phonetics at Cambridge, and inventor of Parseltongue, gave us a special guest lecture on his experiences of creating the language for the Harry Potter films, and how he snuck a lot of interesting linguistics into it (we got to see Praat diagrams of a snake language!). In addition to all this, Daniel Harbour, another colleague at Queen Mary, did a special session on how writing systems develop, and the students came up with their own systems of writing for their languages.
The work that the students did was amazing. We had languages with only VC(C) syllable structures, including phonological rules to delete initial vowels under certain circumstances; writing systems designed to match the technology and history of the speakers (including ox-plough (boustrophedon) systems that zigzagged back and forth across the page); languages where word order varied depending on the gender of the speaker; partial infixed reduplication for paucal with full reduplication for plural; writing systems adapted to be maximally efficient in how to represent reduplication (the students loved reduplication!); circumfixal tense marking with incorporated directionals; independent tense markers appearing initially in verb-initial orders, and a whole ton of other, linguistically extremely cool, features. The most impressive aspect of this, for me at least, was just how creative and engaged the students were in taking quite abstract concepts and using them to invent their language.
For me, and for Coppe, the week was exhausting, but hugely worthwhile. I was really inspired to see what the students could do, and it made me realise more clearly than ever, that linguistics, often thought of as remote, abstract, and forbidding, can be a subject that school students can engage with. For your delectation, here are the posters that the students made for their languages.






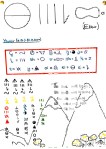


Syntax: still autonomous after all these years!
Another day, another paper. This time a rumination on Chomsky’s Syntactic Structures arguments about the autonomy of syntax. I think, despite Fritz Newmeyer’s excellent attempts to clear this issue up over many years, it’s still reflexively misunderstood by many people outside of generative grammar. Chomsky’s claim that syntax is autonomous is really just a claim that there is syntax. Not that there’s not semantics intimately connected to that syntax. Not that syntactic structures aren’t susceptible to frequency or processing effects in use. Just that syntax exists.
Current alternatives to the generative approach to dealing with language still, as far as I can tell, attempt to argue that syntactic phenomena can be reduced to some kind of stochastic effect, or to some kind of extra-linguistic cognitive semantic structures, or to both. This paper attempts to look at the kinds of arguments that Chomsky gave back in the 1950s and to examine whether the last 60 years have given us any evidence that the far more powerful stochastic and/or cognitive semantic systems now available can do the job, and eliminate syntax. I guess most people that know me will be unsurprised by my conclusion: even the jazziest up-to-the-minute neural net processors that Google uses still don’t come close to doing what a 3 year old child does, and even appealing to rich cognitive structures of the sort that there is good evidence for from cognitive psychology misses a trick when trying to explain even the simplest syntactic facts. I look at recent work by Tal Linzen and colleagues that shows that neural net learners may mimic some aspects of syntactic hierarchy, but fail to capture the syntactic dependencies that are sensitive to such structure. I then reprise and extend an argument that Peter Svenonius and I gave a few years back about bound variable pronouns.
One area where I do signal a disagreement with the Chomsky of 60 years ago is in the semantics of grammatical categories. Chomsky argued that these lack semantics, but, since my PhD thesis back in the early 1990s, I’ve been arguing that grammatical categories have interpretations. Here I try to show that the order of Merge of these categories is a side effect not of their interpretations, but of whether the kind of computational task they are put to is more easily handled with one order or the other.
The idea goes like this (excerpted from section 4 of the paper).
“Take an example like the following:
(20) a. Those three green balls
b. *Those green three balls
As is well known, the order of the demonstrative, numeral and descriptive adjective in a noun phrase follow quite specific typological patterns arguing for a hierarchy where the adjective occurs closest to the noun, the numeral occurs further away and the demonstrative is most distant (Greenberg 1963, Cinque 2005). Why should this be? It seems implausible for this phenomenon to appeal to a mereological semantic structure. I’d like to propose a different way of thinking about this that relies on the way that a purely autonomous syntax interfaces with the systems of thought. Imagine we have a bowl which has red and green ping pong balls in it. Assume a task (a non-linguistic task) which is to identify a particular group of three green balls. Two computations will allow success in this task:
(21) a. select all the green balls
b. take all subsets of three of the output of (a)
c. identify one such subset.
(22) a. take all subsets of three balls
b. for each subset, select only those that have green balls in them
c. identify one such subset
Both of these computations achieve the desired result. However, there is clearly a difference in the complexity of each. The second computation requires holding in memory a multidimensional array of all the subsets of three balls, and then computing which of these subsets involve only green balls.
The first simply separates out all the green balls, and then takes a much smaller partitioning of these into subsets involving three. So applying the semantic function of colour before that of counting is a less resource intensive computation. Of course, this kind of computation is not specific to colour—the same argument can be made for many of the kinds of properties of items that are encoded by intersective and subsective adjectives.
If such an approach can be generalized, then there is no need to fix the order of adjectival vs. numeral modifiers in the noun phrase as part of an autonomous system. It is the interface between a computational system that delivers a hierarchy, and the use to which that system is put in an independent computational task of identifying referents, plus a principle that favours systems that minimize computation, that leads to the final organization. The syntax reifies the simpler computation via a hierarchy of categories.
This means that one need not stipulate the order in UG, nor, in fact, derive the order from the input. The content and hierarchical sequence of the elements in the syntax is delivered by the interface between two distinct systems. This can take place over developmental timescales, and is, of course, likely to be reinforced by the linguistic input, though not determined by it.
Orders that are not isomorphic to the easiest computations are allowed by UG, but are pruned away during development because the system ossifies the simpler computation. Such an explanation relies on a generative system that provides the structure which the semantic systems fill with content.
The full ordering of the content of elements in a syntactic hierarchy presumably involves a multiplicity of sub ordering effects, some due to differences in what variable is being elaborated as in Ramchand and Svenonius’s proposal, others, if my sketch of an approach to the noun phrase is correct, due to an overall minimizing of the computation of the use of the structure in referring, describing, presenting etc. In this approach, the job of the core syntactic principles is to create structures which have an unbounded hierarchical depth and which are composed of discrete elements combined in particular ways. But the job of populating these structures with content is delegated to how they interface with other systems.”
The rest of the paper goes on to argue that even though the content of the categories that syntax works with may very well come from language external systems, how they are coopted by the linguistics system, and which content is so coopted, still means that there is strong autonomy of syntax.
The paper, which is to appear in a volume marking the 60th anniversary of the publication of syntactic structures is on Lingbuzz here.
